Offensive security for MCP servers, or how to prevent AI agent exploits in the wild

Humans interacting with APIs are constrained by judgment; MCP agents are constrained by permissions. Permissions are almost always broader than intent.
The risk that creates is that MCP doesn’t just do what you ask, it does everything it’s allowed to, which in a poorly scoped deployment is a much larger surface than anyone designed for.
MCP demands a security approach that is disciplined without being rigid. If your organization operates in complete isolation, with systems hermetically sealed from the outside world, you might get away without it.
For everyone else, offensive security, especially at scale, is the empirical foundation on which the MCP security posture is built. The following sections explain exactly why.
MCP servers as agent gateways
An MCP implementation establishes a structured JSON-RPC session between:
- MCP hosts
- MCP clients
- MCP servers
- External APIs, databases, and system resources
In contrast to traditional REST APIs, MCP servers dynamically advertise tools and resources; the MCP client can query the server for available capabilities at runtime. This declarative discovery model enables flexible orchestration but changes long-standing security assumptions.
Traditional (REST) API security assumes:
- A human developer predefines endpoint usage.
- Requests are stateless.
- Authentication boundaries are explicit and narrow.
MCP alters this model. It enables an AI system to explore, plan, and execute tool calls autonomously. And this autonomy creates new classes of security risks, especially when privilege boundaries remain broad and imprecise, or when authentication is subpar.
More precisely, many of these risks are extensions or recombinations of established API security failure modes, such as overbroad permissions, confused deputy problems, and injection attacks. Others stem specifically from autonomous planning, language-mediated control, and dynamic capability composition.
Therefore, when an autonomous entity becomes the dominant API consumer, security must adapt from syntax validation to intent validation.
The current challenges of MCP security
Equixly’s security assessment of popular MCP server implementations (Dalla Piazza, 2025) presented sobering data:
- 43% contained command injection flaws.
- 30% were vulnerable to server-side request forgery (SSRF).
- 22% allowed path traversal.
We thought that these types of security vulnerabilities were behind us, largely characteristic of:
- Older web applications
- Early REST/API ecosystems
- Less mature security eras
Yet they appear in the most up-to-date technologies — modern MCP deployments.
Why?

Because MCP implementations often wrap existing APIs with minimal additional security hardening, where:
- Authentication is optional or inconsistent.
- Session identifiers appear in URLs.
- Message integrity controls are lacking.
- Tool metadata exposes high-privilege operations.
The problem in this case is not the protocol itself; it is the tacit assumption that functionality precedes security.
When an MCP server consolidates network APIs and system APIs, it creates a single point of failure. That means a compromise of the server enables orchestrated exploitation across multiple services. This concentration of security risk raises MCP security from an implementation detail to a strategic concern.
Agentic API orchestration and adversarial use cases
MCP changes API consumption from deterministic workflows to exploratory orchestration. An agentic AI system can:
- Chain tool calls.
- Iterate over failures.
- Explore alternative tool paths when encountering constraints.
- Consume responses to refine future actions.
Anthropic and Palo Alto have shown that AI agents can function as highly capable adversarial API clients. Agents don’t just call APIs; they reason across them, chain them, and can decompose a single malicious objective into many individually benign sub-tasks.
Anthropic (2025) reported that a threat actor used MCP servers to build an orchestrated attack framework around Claude Code that integrated with standard penetration-testing tools. That lets the AI carry out most of the intrusion life cycle — from scanning to exploitation and lateral movement — without human operators having to write custom code for each target.
Segal et al. (2025) stated that MCP makes it easier for AI agents to interface with internal data sources and tools. If not properly secured, these connections could expose systems or data and complicate firewall and API gateway inspection.
Examples of agentic AI security vulnerabilities
The following examples illustrate how vulnerabilities arise when AI agents interpret untrusted input and invoke privileged capabilities.
Prompt injection
Prompt injection is one of the most documented attack classes in AI security research. Take the OWASP “2025 Top 10 Risk & Mitigations for LLMs and Gen AI Apps” project as an example. On this top 10 security risk list, prompt injection ranks first, indicating the threat’s severity and frequency.
In an MCP environment, a prompt injection scenario can unfold as follows:
- A malicious document enters the retrieval context.
- The AI agent processes embedded instructions.
- The instructions direct the agent to invoke a privileged MCP tool.
- The tool accesses internal APIs.
- Sensitive data leaves the system.
This chain requires no traditional exploit payload; it exploits semantic trust. And it is worth noting that the chain is only possible if:
- The system does not strictly separate data from instructions.
- Tool invocation is not gated by policy validation.
- There is no context trust boundary enforcement.
- Output filtering/egress controls are subpar.
Another important point is that, in most agentic systems, chaining occurs via APIs. Here’s the typical flow:
- Malicious content enters the context, say via RAG (retrieval-augmented generation).
- The model interprets embedded instructions.
- The model triggers a tool call.
- The tool is implemented as a wrapper around an internal API.
- The API returns data.
- The model includes that data in its response.
Tool poisoning
Another serious security risk is tool poisoning, which is the malicious manipulation of tool metadata, descriptions, or input expectations. In an MCP server environment, it occurs at two layers:
-
At the agent layer, manipulated tool descriptions or schemas can cause the model to:
- Select an inappropriate tool.
- Generate unsafe parameters.
- Invoke tools in unintended contexts.
-
At the implementation layer, if the underlying tool is insecure, additional risks arise, such as:
- Poor input validation allows command injection.
- Insufficient path restrictions enable arbitrary file reads, that is, path traversal.
- Unrestricted URL fetchers lead to server-side request forgery.
In this case, the AI agent becomes an unwitting participant. Adversaries manipulate it at the semantic layer, which puts them in a perfect position to trigger exploitation at the application layer.
Consider that the effects of tool poisoning materialize through APIs as well, even though the poisoning itself is not an API attack per se:
- The AI agent, influenced by poisoned information, generates a tool call.
- The tool call is typically an API request to a backend service.
- The backend executes the request.
This is where MCP security meets the API layer beneath it.
API foundations: Securing the layer beneath MCP
As hinted before, much of what happens in the MCP context rests on APIs. APIs expose:
- Identity enforcement
- Business logic
- Data boundaries
An MCP server is just a translation layer; it wraps APIs, providing a standardized way for artificial intelligence to understand how to interact with them. But it doesn’t replace the underlying business logic, access controls, or data boundaries.
Consequently, if the APIs contain inherent flaws or are susceptible to manipulation, the MCP layer is jeopardized. Moreover, if the API foundation is shaky, MCP will only facilitate exploitation.
For instance, an API may suffer from BOLA (broken object-level authorization). Via prompt injection, an AI agent can request data belonging to User B while acting on behalf of User A. Since MCP servers often aggregate credentials, they can become confused deputies, where the server has high-level permissions but fails to verify if the intent of the agent’s request matches the specific user’s permissions.
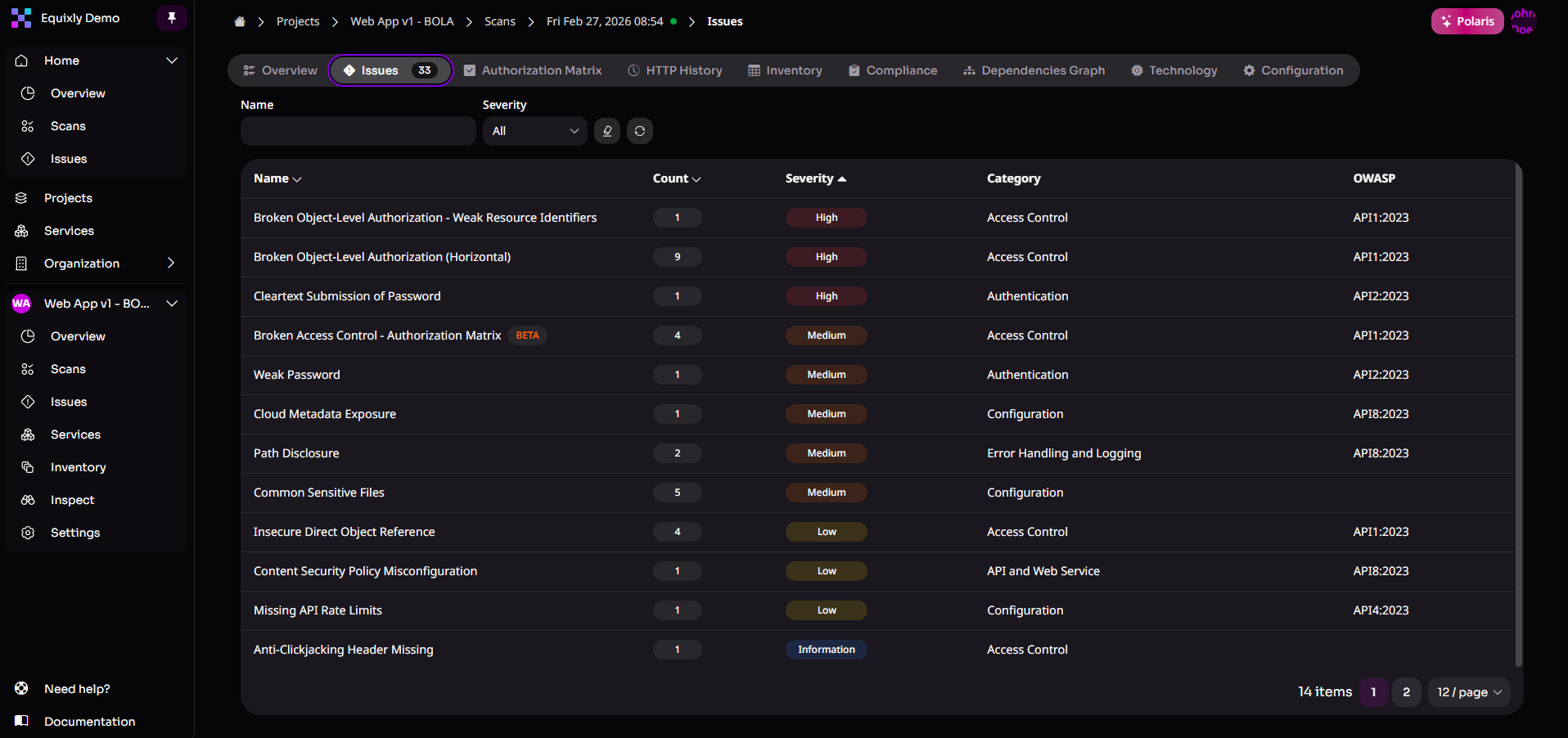
The corollary is that MCP security must include API security as an integral part.
Toward offensive MCP security
Given these architectural properties and attack patterns, defensive controls alone cannot provide sufficient assurance. Static code review and perimeter controls do not reliably model:
- Multi-step tool call chains
- Non-deterministic output paths
- Runtime connector states
- Edge-case parameter combinations
These risks require a dynamic, proactive, offensive approach as a core element in building a robust MCP security posture.
The MCP ecosystem exists in a continuous state of pressure. Because MCP servers use a declarative discovery model, the attack surface is not merely a list of endpoints but a fluid landscape of potential tool combinations that an AI agent can navigate in ways a human developer never intended.
Offensive security is indispensable in this environment. It offers the only empirical proof of a system’s resilience, revealing what can happen when an agent encounters an unforeseen logic flaw or a confused deputy scenario.
However, traditional point-in-time manual penetration testing is incompatible with the pace of MCP development. It represents only a snapshot of a moving target, but MCP environments change whenever someone updates tool metadata or deploys a new model version.
Scaled adversarial testing bridges this gap by using agentic AI to test AI agents. This AI-vs-AI model enables:
- Continuous discovery of vulnerabilities as soon as new tools are added.
- Exhaustive probing of parameter combinations and tool-chaining sequences that would take humans weeks to simulate.
- Behavioral validation that makes it possible for security boundaries to remain intact as agent behaviors evolve.
The ‘Agentic AI Hacker’: Convergence of API, MCP, and GenAI validation
Equixly addresses the unpredictability of MCP environments through its Agentic AI Hacker.
It’s an autonomous engine that uses machine learning — specifically, reinforcement learning — to emulate the adversary’s reasoning and approach. In essence, it’s a unified testing platform that bridges the gap between raw infrastructure and agentic orchestration.
The basis: API security
Equixly’s primary focus is on APIs, which, generally speaking, underpin modern software — from web to LLM applications.
Hence, the Agentic AI Hacker is trained to autonomously identify logic flaws, such as BOLA, as well as technical vulnerabilities, such as SSRF. It covers the entire OWASP Top 10 API security risks list but extends beyond it to identify business logic vulnerabilities that do not fit easily into existing cybersecurity frameworks and categories.
The medium: MCP testing
The Agentic AI Hacker connects to MCP servers and uses MCP’s built-in discovery mechanisms to enumerate exposed tools and resources. It then performs automated vulnerability testing against them.
It searches for critical implementation flaws — command injection, path traversal, remote code execution, etc. — allowing security teams to proactively detect and remediate weaknesses in MCP deployments before attackers exploit them.
From this perspective, Equixly can be construed as an MCP-aware penetration testing solution developed for the emerging agentic ecosystem.
The top: GenAI and LLM security assessment
Using a controlled form of agentic AI, the AI Hacker emulates adversarial behavior through a perception–reasoning–action loop:
- Maps the LLM environment.
- Discovers multi-step exploitation paths.
- Executes targeted attack scenarios with deterministic and repeatable results.
The objective is to automatically find LLM-specific risks — such as prompt injection, excessive agency, insecure output handling, misinformation, and unsafe decision-making patterns — in large language model applications exposed via APIs.
Conclusions
MCP provides a standardized way for AI systems to interact with external tools. It removes the need for a slew of custom connectors and makes it easier to build agent-based workflows.
However, MCP servers also centralize access, permissions, and runtime discovery into a single orchestration layer. And there, security vulnerabilities can arise through chained tool calls and API-driven actions that passive defenses don’t reliably capture. Because of this concentration of capabilities, risk is distributed differently and must be tested continuously.
Adversarial testing provides the clearest picture of how secure an MCP deployment actually is. It stresses the system under conditions that echo those created by actual threat actors and shows whether security boundaries hold as agents and tools change.
Moreover, an AI agent can move through a toolchain at machine speed, and attackers can direct this behavior in unintended ways. Scaled offensive security is the most reliable way to determine whether an MCP deployment can withstand real-world exploitation.
Equixly’s Agentic AI Hacker applies this approach in practice, continuously testing APIs, MCP servers, and LLM-driven workflows to proactively find vulnerabilities before threat actors exploit them.
Reach out: let’s talk about how we can help you validate and strengthen the security of your MCP deployments.
FAQs
Why is offensive security important for MCP servers?
Considering that MCP environments allow AI agents to discover and chain tools dynamically, only continuous adversarial testing can reveal vulnerabilities that static analysis and perimeter defenses miss.
How do MCP servers increase security risk compared to traditional APIs?
MCP servers centralize tool access, credentials, and runtime discovery into a single orchestration layer, which leaves room for AI agents to autonomously explore and invoke APIs in ways developers do not anticipate.
How does Equixly help secure MCP deployments?
Equixly’s Agentic AI Hacker automatically tests APIs, MCP servers, and LLM-driven workflows to identify exploitable vulnerabilities before attackers can use them.

Zoran Gorgiev
Technical Content Specialist
Zoran is a technical content specialist with SEO mastery and practical cybersecurity and web technologies knowledge. He has rich international experience in content and product marketing, helping both small companies and large corporations implement effective content strategies and attain their marketing objectives. He applies his philosophical background to his writing to create intellectually stimulating content. Zoran is an avid learner who believes in continuous learning and never-ending skill polishing.