Distributed coordination without the infrastructure overhead
How we leveraged PostgreSQL to build distributed primitives and eliminate an entire layer of infrastructure dependencies
The challenge: Coordinating multiple processes at scale
At Equixly, we run highly available distributed applications, where multiple processes need to coordinate access to shared resources. As our platform grew, we faced increasingly complex synchronization challenges: rate-limiting API calls across multiple servers, ensuring only one process handles each task, and sharing configuration state that survives process crashes.
We were aware of several distributed coordination tools available on the market: Redis, etcd, ZooKeeper, Hazelcast, and Memcached. These are excellent, battle-tested solutions used by companies worldwide.
However, adopting any of them meant introducing a new infrastructure dependency—another service to deploy, monitor, secure, and maintain. Furthermore, we needed to ensure high availability for this coordination layer, which would add complexity to our disaster recovery plans.
We also considered building a custom clustering solution. While this approach would have given us full control, it was a significant undertaking that did not generate direct business value. The effort required to build, test, and maintain a reliable distributed consensus system was hard to justify when our core business goal lay elsewhere.
We took a step back and asked ourselves a fundamental question: “Do we really need another service, or can we leverage what we already have?” Looking at our existing stack, the answer was sitting right there: PostgreSQL.
Every one of our applications already depended on PostgreSQL for data persistence. It was already deployed, highly available, and understood by the entire team. What if we could use it for distributed coordination, too?
Why PostgreSQL? The hidden features most teams never use
PostgreSQL is typically seen as ‘just a database,’ that is, a place to store and query data. But under the hood, it offers powerful features that most applications never fully utilize:
- Advisory locks: Application-level locks that do not require actual table rows to exist. They are automatically released when a transaction ends, even if the process crashes.
- LISTEN/NOTIFY: A built-in pub/sub messaging system that allows database connections to send and receive notifications instantly.
- Row-level locking: Atomic operations using SELECT FOR UPDATE and INSERT … ON CONFLICT that guarantee consistency without application-level transactions.
These features, combined with PostgreSQL’s ACID guarantees and decades of battle-testing, made it a compelling foundation for distributed coordination. The key insight was that we were not adding a new dependency; we were using an existing one more effectively.
Our decision: Build instead of buy
After evaluating the trade-offs, we decided to build a Go library that provides distributed coordination primitives backed entirely by PostgreSQL. We called it PgDist, which is short for PostgreSQL Distributed Coordination.
This move wasn’t a decision we took lightly. Building infrastructure components in-house carries risks: maintenance burden, potential bugs, and the opportunity cost of not using proven solutions.
However, in our specific case, the benefits outweighed the risks:
- Zero additional infrastructure: No new services to deploy or maintain
- Unified operational model: Same monitoring, backup, and HA strategies as our data layer
- Team expertise: Everyone already knew PostgreSQL, so there were no new technologies to learn
- Cost efficiency: No additional licensing or infrastructure costs
The goal was clear: provide the coordination primitives we needed—semaphores, locks, key-value storage, and atomic variables—without adding complexity to our infrastructure.
The architecture
The beauty of PgDist lies in its simplicity. Multiple application instances coordinate through the same PostgreSQL database they already use for data storage:
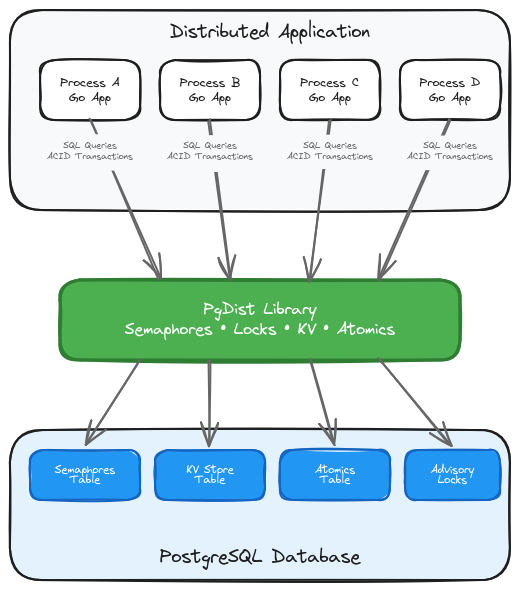
No message brokers. No coordination services. Just your existing database infrastructure doing what it does best: managing concurrent access to shared state.
| What PgDist Offers | |
|---|---|
| Primitive | Use Case |
| Weighted semaphore | Rate-limiting, connection pooling, resource quotas |
| Read-write locks | Coordinating readers and writers across processes |
| Key-value store | Shared configuration, session data, feature flags |
| Atomic variables | Distributed counters, metrics, boolean flags |
All of these primitives are:
- Persistent: Survive process crashes
- Thread-safe: Work across goroutines and processes
- FIFO-fair: Serve requests in order (for semaphores)
- Self-healing: Clean up stale locks from crashed processes automatically
Key design decisions
When we started building PgDist, we had to make several architectural choices that would shape the library’s behavior and performance characteristics. Each decision was driven by our goal of leveraging PostgreSQL’s native capabilities while keeping the implementation simple and reliable.
For read-write coordination, we chose to use PostgreSQL’s advisory locks. These are application-level locks that exist independently of any table rows; you request a lock on an arbitrary numeric key, and PostgreSQL handles the rest.
What makes them particularly valuable for our use case is their automatic cleanup behavior: when a transaction ends—whether through commit, rollback, or even a process crash—PostgreSQL automatically releases the lock. That gave us read-write lock semantics essentially for free, with built-in crash recovery that we do not have to implement ourselves.
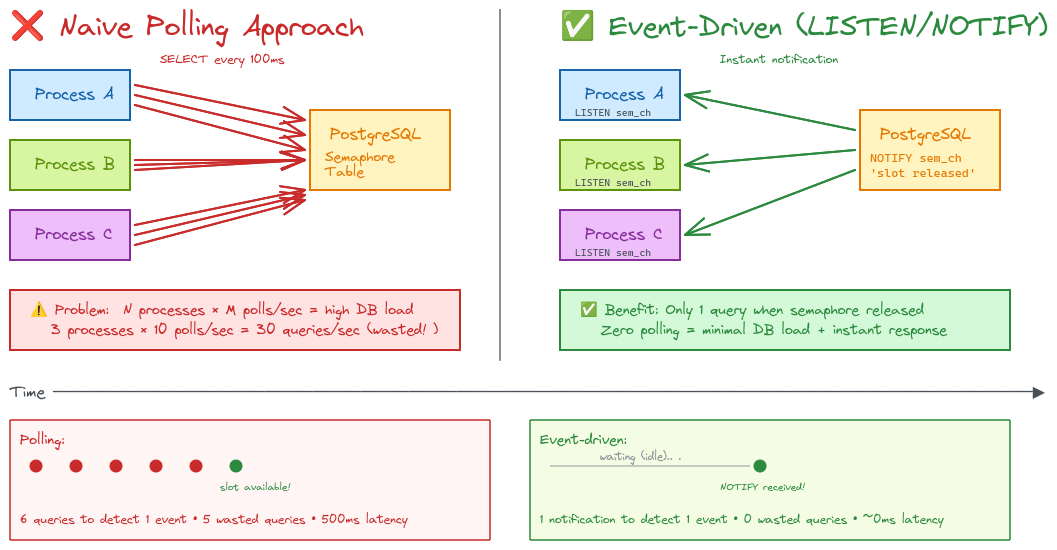
The semaphore implementation presented an interesting challenge. The naive approach was to poll the database repeatedly to check whether a semaphore has available capacity. However, this would have created unnecessary load on the database, especially when many processes are waiting for the same resource.
Instead, we built our semaphores on top of PostgreSQL’s LISTEN/NOTIFY mechanism. When a process releases a semaphore, it sends a notification through PostgreSQL. All waiting processes receive this notification instantly and can attempt to acquire the resource. This event-driven approach dramatically reduces database load compared to constant polling.
For atomic variables, we designed every operation as a single SQL statement using PostgreSQL’s row-level locking. The key technique is using INSERT … ON CONFLICT DO UPDATE combined with carefully crafted WHERE clauses.
PostgreSQL guarantees that the WHERE clause is re-evaluated after acquiring the row lock, which means all operations are truly atomic. There are no race conditions, even when multiple processes attempt the same operation simultaneously. This approach eliminates the need for application-level transactions and the complexity it entails.

Finally, we had to address the problem of stale locks. What happens when a process acquires a semaphore and then crashes before releasing it? Without intervention, that capacity would be lost forever.
PgDist solved this problem by running configurable background monitors (only one will check, as the leader) that periodically check for stale acquisitions based on specified time-to-live values. When a lock has not been refreshed within its TTL, the monitor assumed the owning process has crashed and released the lock. The system heals itself automatically.
Trade-offs we accepted
Every architectural decision involves trade-offs, and we wanted to understand what we were giving up in exchange for the simplicity of using PostgreSQL.
The most significant trade-off is latency. Every coordination operation requires a round-trip to the database, which means we operate in the millisecond rather than microsecond range. For our use cases—rate-limiting API calls, coordinating batch jobs, managing feature flags, etc.—this latency is perfectly acceptable.
We also had to accept limitations around connection pooling. PgDist requires direct connections to PostgreSQL because external connection poolers, such as PgBouncer, break both advisory locks and LISTEN/NOTIFY when running in transaction mode.
Since advisory locks are tied to database sessions, connection poolers that multiplex sessions will cause them to behave unpredictably. Similarly, NOTIFY messages are delivered to specific connections, which poolers may reassign between queries.

The most philosophical trade-off is our increased dependency on PostgreSQL. If the database goes down, so does our coordination layer. But we realized this was actually a non-issue: if PostgreSQL is down, our applications do not function anyway because they depend on it for data.
We did not introduce a new failure mode; we acknowledged an existing one. In fact, consolidating coordination into PostgreSQL reduced our overall failure surface compared to running a separate coordination service.
Results and benefits
After deploying PgDist in production, the benefits became clear across multiple dimensions.
From an operational perspective, we eliminated an entire category of infrastructure concerns. There is no separate coordination service to deploy, no additional monitoring dashboards to watch, and no extra runbooks for the on-call team to learn. When PostgreSQL fails over, our coordination layer fails over with it. The unified operational model has been a tremendous win for us.
The cost savings were immediate and tangible. We avoided the infrastructure costs of running a separate, highly available coordination service. That meant no additional compute instances, extra load balancers, or separate storage. We also avoided the hidden costs of operational complexity: the time spent debugging coordination service issues and the cognitive load of maintaining expertise in another distributed system.
The experience has been remarkably smooth. Everyone on the team already knows SQL, so debugging coordination issues is straightforward—query the tables and see what happens. Testing is simple, too: spin up a PostgreSQL container, and your tests have a fully functional coordination layer. There is no need to mock a complex distributed system or run heavyweight test infrastructure.
We also got high availability essentially for free. Since PgDist relies entirely on PostgreSQL, we automatically benefit from whatever HA setup we already have in place.
If you run on AWS RDS, Google Cloud SQL, or Azure Database for PostgreSQL, you already have built-in replication, automatic failover, and point-in-time recovery. No extra HA configuration is needed for coordination; if your database is highly available, so is your distributed coordination layer.
Lessons learned
Building PgDist taught us lessons that extend beyond this specific project.
The most important lesson was to question our dependencies before adding new ones. It is easy to reach for a specialized tool when facing a new problem, and often it is the right choice. Still, it is worth pausing to ask whether existing infrastructure could adequately solve the problem. In our case, PostgreSQL had capabilities we had never explored before, and using them substantially reduced our complexity.
We also gained a deeper appreciation for what some call “boring technology.” PostgreSQL is not exciting. It does not have the buzz of newer distributed systems. But that is precisely why it is perfect for critical infrastructure. It is proven, documented, and understood.
The constraints of using a relational database actually pushed us toward better solutions. When you cannot rely on fancy distributed protocols, you have to think carefully about what is truly necessary. Single-statement atomicity proved simpler and more elegant than distributed transactions. Sometimes limitations are hidden features.
Conclusion
PgDist emerged from a simple question: “Do we really need another service for this?”
By leveraging PostgreSQL’s powerful but often overlooked features, we built a complete distributed coordination system without adding infrastructure complexity. Our semaphores, locks, key-value store, and atomic variables all run on the same database infrastructure we were already using.
Distributed systems tools like Redis and etcd are excellent solutions that scale well, but deciding whether to use them requires a case-by-case evaluation. In our case, the decision to leverage PostgreSQL reduced our infrastructure footprint and simplified operations. It also gave us coordination primitives that inherit the high availability and reliability of our existing database layer.
Sometimes the best solution is not a new tool: it is a better understanding of the tools you already have.
Questions about PgDist and Equixly? Get in touch.

Andrea stocchero
Lead Software Engineer
Andrea's comprehensive expertise spans programming, automation, and cloud solutions, marking a career of innovation and leadership. He led multiple competency centers, emphasizing cloud computing and modern integrations like container adoption. Serving pivotal roles at UniCredit Bank, Andrea introduced transformative projects and championed integrating cutting-edge technologies, such as virtual reality for business visualization. As a Senior Cloud Architect, he designs versatile cloud solutions and actively embraces new tech innovations. Finally, Andrea has significantly supported the open-source world, especially the Chart.js project, being one of the main contributors.