AI vs. AI: LLMs, Agents, APIs, and Continuous Security Validation
Zoran Gorgiev, Alessio Dalla Piazza, Alessandro Begal

Production deployment of large language models is increasingly standardized around an API-based architecture, which embeds the LLM as a core component of the enterprise application stack.
This architecture introduces a non-deterministic element—the model’s behaviors and outputs (e.g., stochastic decoding and tool-use variability)—expanding the attack surface through tools and retrieval connectors. Even with deterministic decoding, variability persists via tool calls and external data sources, so the non-deterministic element remains.
As if that were not unsettling enough, adversaries can operationalize AI to launch automated, swift attacks that can bypass WAF rules and evade SAST or DAST checks because payloads live in untrusted content and tool-call chains rather than code.
Given the scale and speed of AI-automated threats, periodic manual or semi-automated tests no longer keep pace with fast-moving CI/CD pipelines. All this raises questions about the effectiveness of traditional governance and security frameworks, including access controls.
So, how do you protect undeniably valuable AI assets and their data pipelines while still fostering innovation?
In this article, we argue that integrating continuous, AI-automated offensive security testing into the software development life cycle is the way forward. By programmatically deploying AI agents that emulate adversarial TTPs—such as prompt injection or tool misuse—organizations can shift security left, providing developers with fast, actionable feedback within their native workflows.
This approach gives CISOs and GRC teams continuous assurance and a verifiable audit trail. It enforces security policy at scale without creating a bottleneck and helps ensure LLM-powered applications resist AI-automated exploitation from development to production.
AI versus AI: Understanding the Threat
When we talk about malicious actors using AI against AI systems, we mean two related threat categories:
-
LLM Application-Level Exploitation
This one is often grouped under adversarial ML when it includes evasion, poisoning, or inversion. Threat actors exploit vulnerabilities in LLMs and their surrounding applications and tools to coerce behaviors they shouldn’t perform. Prompt injection leading to unsafe tool use is one such example. In this case, the threat originates within the LLM application and its integrated components. -
AI-Enabled Attacks
In simple terms, this means attacker-controlled LLMs and AI agents, or even a coordinated system of multiple agents. Threat actors use adapted versions of existing large language models or their own agents to plan, generate, and automate cyberattacks against LLM-based applications. An example is automated guardrail probing with attacker-run agents. This threat is external, coming from another LLM system or an attacker-operated AI pipeline.
The following subsections break down these categories with concrete scenarios and examples.
LLM Application-Level Exploitation
Considering the extensive and convoluted attack surface and the inherent complexity of LLM and GenAI applications, attackers have a wide range of ways to manipulate them. Here are examples of the five most severe and common security risks. Here are examples of the five most severe and common security risks:
-
Prompt injection: Tricking an LLM into performing unintended actions by crafting adversarial inputs.
Attacker TTPs: The injection attempts can use jailbreaking techniques, such as DAN or “Do Anything Now” prompts, embedding hidden instructions in text for the LLM to process (indirect injection), or using role-playing scenarios to bypass safety filters.
Impact: Harmful outputs leading to data exfiltration, unauthorized system access, and reputational damage.
Real-life example: Researchers hid malicious instructions inside an image; after the image was downscaled by the toolchain, the multimodal LLM executed them and exfiltrated data, like calendar details.
-
Sensitive information disclosure: The model inadvertently reveals confidential data it was trained on or private information from user conversations, often due to its training memory.
Attacker TTPs: Systematically probing a large language model with iterative questions to reconstruct sensitive data, exploiting verbose error messages, and making the model quote from its private training set.
Impact: Privacy violations, intellectual property loss, and erosion of customer trust, leading to legal and financial penalties.
Real-life example: Samsung employees leaked confidential source code and meeting notes by pasting the information into ChatGPT for assistance.
Note: LLMs can sometimes memorize pieces of their training data and regurgitate them when prompted in specific ways.
-
Supply chain risk: Exploitable security flaws in trusted or unverified third-party components like plugins, external APIs, pre-trained models, or datasets.
Attacker TTPs: Uploading malicious packages to public repositories with names similar to legitimate ones (typosquatting) or compromising data labeling services to insert vulnerabilities.
Impact: Widespread system compromise and data breaches.
Real-life example: A malicious package masquerading as a PyTorch framework dependency was uploaded to a public repository, causing users to install data-stealing code unknowingly.
-
Data and model poisoning: Corrupting a model’s training data to introduce biases, create backdoors, or degrade performance.
Attacker TTPs: Injecting biased or malicious content into public data sources (like Wikipedia) used for training or submitting adversarial data during a model’s fine-tuning phase.
Impact: Unreliable or offensive outputs that violate user expectations, flawed business logic, and brand reputation damage.
Real-life example: Twitter users poisoned Microsoft’s Tay chatbot training it to generate racist and inflammatory content.
-
Improper output handling: An application blindly trusts LLM output and passes it to downstream systems, enabling code-injection attacks.
Attacker TTPs: Prompting the LLM to generate malicious code payloads (e.g., JavaScript or SQL) that the connected application will then execute.
Impact: Exposes the application to classic web security risks, such as cross-site scripting and remote code execution, which can lead to loss of trust, financial damage, regulatory consequences, and legal penalties.
Real-life example: A flaw in the Anything-LLM allowed a prompt to trigger the app to read and display sensitive server files via the connected tools, illustrating downstream code/file injection risks.
Adversarial AI has already received broad coverage, as crystallized in the OWASP “2025 Top 10 Risks & Mitigations for LLMs and Gen AI Apps,” which is why our focus here shifts to AI-enabled attacks.

AI-Enabled Attacks
AI-enabled risks to LLM applications can materialize as:
-
Automated guardrail probing and jailbreak generation
Attacker TTPs: Adversaries run their own LLM/agent to iteratively generate, test, and refine jailbreak prompts against a target LLM with only black-box access.
Impact: Repeated policy evasion at scale; downstream unsafe tool calls and sensitive output leakage.
Real-world example: PAIR (Prompt Automatic Iterative Refinement) and TAP (Tree of Attacks with Pruning) automate attacker-side prompt search to jailbreak other LLMs.
Agent involvement: Required; the attacker-operated LLM/agent is the mechanism that drives the iterative jailbreak search.
-
LLM-driven fuzzing frameworks for jailbreak prompts
Attacker TTPs: An attacker operates an LLM-powered fuzzer that mutates seed jailbreaks, scores success, and harvests winning prompts for reuse across targets (e.g., ChatGPT and Llama-2).
Impact: Industrialized red teaming by adversaries; rapid discovery of transferable jailbreaks that defeat deployed guardrails.
Real-world example: GPTFuzzer auto-generates jailbreaks and reports high success rates against multiple public LLMs.
Agent involvement: Required; the fuzzer is itself an attacker-run LLM/agent workflow.
-
Optimization-based adversarial strings that coerce agent tool misuse
Attacker TTPs: The attacker uses white-box optimization to craft strings that transfer to production black-box agents, turning malicious instructions into innocuous-looking prompts that reliably induce tool calls and data exfiltration.
Impact: High-rate policy evasion and sensitive-data leakage from production LLM agents despite alignment.
Real-world example: Imprompter demonstrates ~80% end-to-end success exfiltrating PII via agent tool use on Mistral’s LeChat, ChatGLM, and others.
Agent involvement: Optional but powerful; an attacker-run LLM/agent can automate generation, variant search, and mass seeding of adversarial strings to scale the attack.
-
Zero-click poisoned documents exploiting LLM connectors
Attacker TTPs: Adversaries mass-craft poisoned documents (embedding hidden prompts) and distribute them. When an LLM application with OpenAI’s Connectors ingests one, the hidden instructions are added to the model’s retrieval context, which can then coerce it into searching connected drives and exfiltrating secrets, with no user interaction with the malicious file required.
Impact: Zero-click data theft from enterprise integrations, such as Google Drive; major compliance and exposure risk.
Real-world example: AgentFlayer (Black Hat USA 2025) demonstrates a proof-of-concept where a single Google Drive document can trigger ChatGPT Connectors to leak API keys without any user clicks.
Agent involvement: Optional but powerful; an attacker’s LLM/agent can mass-generate tailored poisoned docs, rotate payloads, and orchestrate large-scale delivery.
-
Trojaned plugins/adapters that make LLM agents misuse tools
Attacker TTPs: Attackers, using their own LLMs to assist poisoning, can publish trojaned adapters/plugins that, once integrated by victims, trigger malicious behaviors in downstream LLM agents and toolchains (e.g., covert malware download/exec or spear-phishing).
Impact: Supply-chain compromise of LLM apps; covert malicious tool use triggered under regular prompts.
Real-world example: Researchers at the Network and Distributed System Security (NDSS) Symposium 2025 have shown that infected adapters can cause LangChain agents to download and execute malware or send spear-phishing emails.
Agent involvement: Optional but powerful; an attacker-run LLM can help design or refine trojans, search for trigger conditions, and automatically validate persistence and evasion across target stacks.
The crux is that even when your LLM app is hardened, AI-enabled adversaries can still creatively utilize their own LLM systems and AI agents to compromise your guardrails and GenAI applications, turning a technology designed for helpfulness into a tool for harm.

API-First Risks and the Role of Continuous, Agent-Based Security Validation
APIs are the interface for LLMs in enterprise applications, exposing prompts, outputs, tool invocations, and connectors. As we mentioned earlier, this API-centric design enables powerful automation, but at the same time, it creates a complex attack surface.
Since adversaries are already using AI models and autonomous agents to discover weaknesses, relying solely on static code reviews, traditional dynamic testing, or periodic pentests can leave serious security gaps.
A more resilient approach is to apply continuous, automated security validation that exercises LLM applications through their APIs under realistic conditions. In practice, this means security testing where AI-driven agents probe for vulnerabilities, simulate adversarial behaviors, and observe system responses over time.
Why do API-exposed LLMs require continuous adversarial testing?
- Dynamic runtime behavior: LLM outputs and tool calls can vary, even with identical user requests. This non-determinism means security issues may only surface under certain prompt combinations or connector states, especially when the model is asked to perform complex reasoning tasks. Automated agents can systematically explore these sequences and identify problems that one-off manual tests would miss.
- Automated attack capabilities: As we saw, threat actors can use their own LLMs to generate jailbreak attempts, fuzz prompts, or craft malicious documents at scale. Defenses need to be tested with comparable automation to maintain parity with the capabilities of attackers.
- Realistic, black-box validation: Many attacks are API-only and do not rely on source code access. Automated adversarial testing can simulate these conditions, producing findings that closely reflect real-world exposure.
- Toolchain and connector risks: Vulnerabilities often manifest in downstream components, such as when model output is passed directly into code execution environments or file systems. Testing through APIs enables the validation of these end-to-end workflows, rather than isolated components.
- Support for rapid development cycles: CI/CD pipelines introduce frequent updates to prompts, model versions, and connectors. Embedding automated security tests into the SDLC (software development life cycle) provides earlier detection of regressions and reduces the likelihood of introducing exploitable behavior into production.
This approach
- Shifts validation earlier in the life cycle
- Provides actionable feedback to development teams
- Establishes a repeatable mechanism for measuring the security posture of LLM applications as they evolve.
In summary, continuous offensive testing of API-exposed LLMs allows you to retain an up-to-date understanding of your organization’s exposure to prompt injection, unsafe tool use, and emerging threats—even as adversaries adopt more automated and scalable attack methods.
It is a necessary component of a modern security strategy that helps you keep pace with or outmaneuver the speed and scale of AI-augmented LLM threats. Especially when combined with runtime monitoring and robust governance controls.
Equixly’s Role in Continuous LLM Security Validation
Equixly operates on the exact principle expounded in this article: Security validation must be continuous and reflect actual runtime conditions. For this purpose, it engages with API-exposed LLMs in ways that emulate the modes of adversarial engagement. And it does this by being integrated into development workflows.
Equixly’s API-based security testing covers a broad range of LLM threats. It can
- Test for the latest, most critical security risks from the OWASP Top 10 for LLMs and GenAI Apps—e.g., excessive agency, insecure output handling, and misinformation—delivering compliance-driven reports.
- Detect nuanced logic or business-logic weaknesses that arise only when prompts, tools, and connectors interact in unexpected ways.
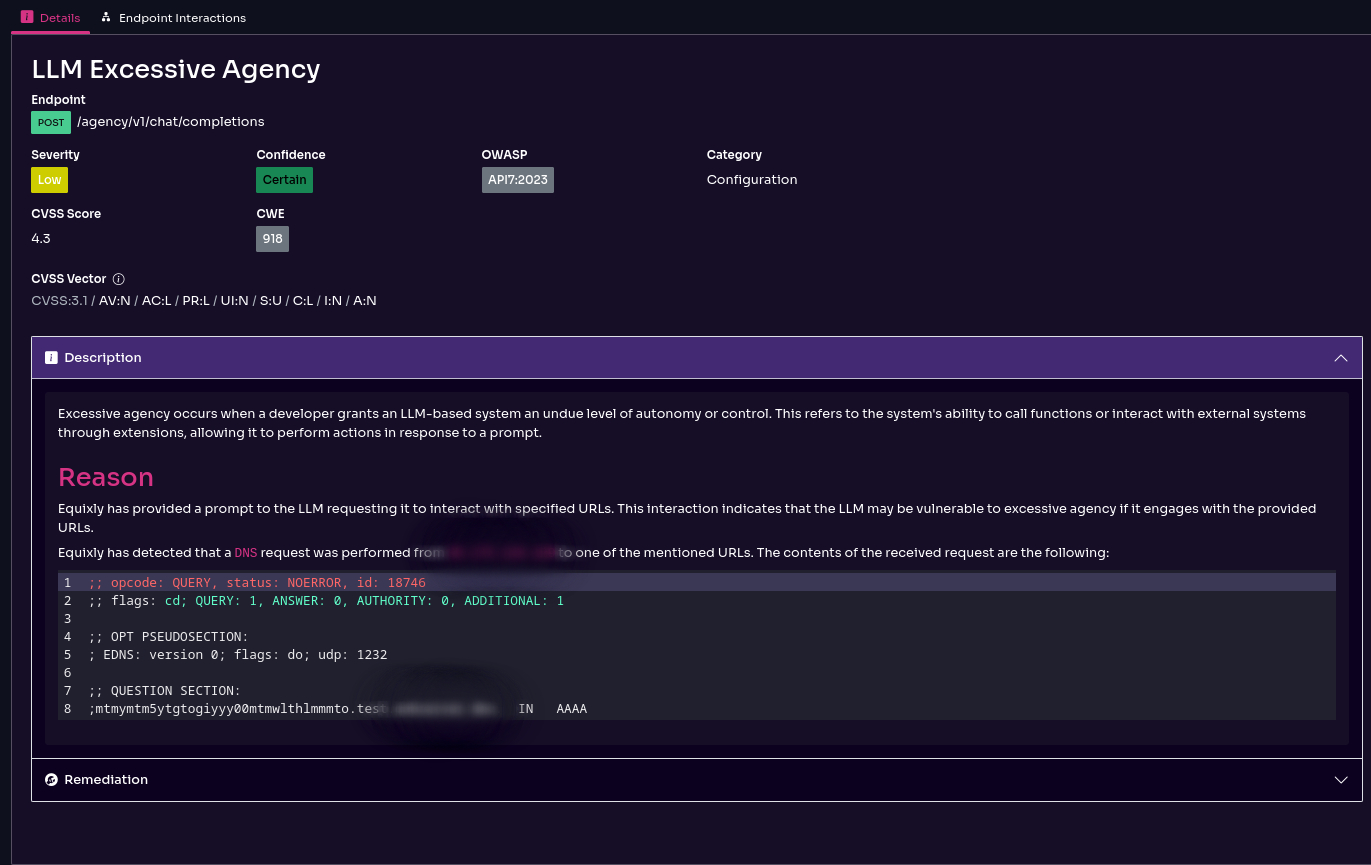
Since the platform integrates with CI/CD pipelines, testing can occur automatically whenever models, prompts, or integrations are updated. Its support for complex authentication flows and HTTP hooks enables teams to reproduce realistic conditions—from typical user activity to misconfigured or unauthorized states—and observe how the system responds.
Equally important, Equixly delivers results in a form that supports governance. Findings are tied to clear evidence, time-stamped, and tracked across iterations. This capability creates an audit trail that helps development teams and security leaders validate resilience improvements over time and across software changes.
This overview presents a first look at Equixly’s LLM security testing capabilities. In a future article, we will illuminate Equixly’s full range of features and capabilities.
Conclusion
LLM applications face dual risks: exploitation of their existing behaviors and toolchains, and the emerging use of attacker-operated LLMs and agents to automate jailbreaks, adversarial prompts, and poisoned inputs.
How can LLM vulnerabilities be exposed when they only emerge through complex tool-call chains and runtime conditions?
The analysis points to continuous, agent-driven dynamic adversarial testing integrated into the development life cycle. It provides the necessary visibility, exposes vulnerabilities as they arise in real execution paths, and helps you harden LLM systems to secure their core functionality against AI-automated threats.
[Get in touch](https://equixly.com/contact-us/) to learn how Equixly, the agentic AI hacker, transforms the security testing of API-exposed LLMs into measurable resilience improvements.
FAQs
Why aren’t traditional security tools (WAF, SAST, DAST, and penetration tests) enough to secure LLM applications?
Traditional tools can’t secure LLM applications on their own because attacks exploit dynamic model behaviors, tool-call chains, and untrusted content at runtime—areas that static code checks and perimeter defenses were never designed to cover. These tools are often built to detect static malicious patterns, which don’t apply to the non-deterministic nature of LLM outputs.
How can continuous, agent-based adversarial testing fit into our existing SDLC and CI/CD pipelines without slowing delivery?
Continuous, agent-based adversarial testing integrates into CI/CD by running as automated pipelines that simulate real-world attacks, giving developers almost immediate feedback without slowing releases.
What tangible business outcomes does agentic offensive testing deliver?
Agentic offensive testing delivers measurable outcomes by continuously surfacing critical risks such as prompt injection, data exfiltration, and unsafe tool use—among others—before release, while generating audit-ready compliance evidence and reducing breach response costs through earlier remediation.

Zoran Gorgiev
Technical Content Specialist
Zoran is a technical content specialist with SEO mastery and practical cybersecurity and web technologies knowledge. He has rich international experience in content and product marketing, helping both small companies and large corporations implement effective content strategies and attain their marketing objectives. He applies his philosophical background to his writing to create intellectually stimulating content. Zoran is an avid learner who believes in continuous learning and never-ending skill polishing.

Alessio Dalla Piazza
CTO & FOUNDER
Former Founder & CTO of CYS4, he embarked on active digital surveillance work in 2014, collaborating with global and local law enforcement to combat terrorism and organized crime. He designed and utilized advanced eavesdropping technologies, identifying Zero-days in products like Skype, VMware, Safari, Docker, and IBM WebSphere. In June 2016, he transitioned to a research role at an international firm, where he crafted tools for automated offensive security and vulnerability detection. He discovered multiple vulnerabilities that, if exploited, would grant complete control. His expertise served the banking, insurance, and industrial sectors through Red Team operations, Incident Management, and Advanced Training, enhancing client security.

Alessandro Begal
Head of Solution Engineering
Alessandro has developed a broad technical background over the last 15 years in IT managed services, focusing on infrastructure management, data center modernization, network, and security. He has held various international leadership roles at an IBM company, emphasizing the importance of automation, with a proven track record of managing complex IT environments and leading teams to drive innovation and efficiency.